L’età dei Petabyte
5 min read
Le tecnologie moderne possiedono un genere di memoria che dimentica. Tale tecnologie divengono rapidamente obsolete, sono volatili e riscrivibili. Vecchi documenti digitali possono diventare inutilizzabili poiché la corrispondente tecnologia — si pensi al caso di lettori floppy o di vecchi processori — non è più disponibile.
Vi sono milioni di pagine abbandonate su Internet: pagine che, una volta create, non sono state più aggiornate o modificate. All’inizio del 1998, la vita media di un documento o di una pagina non abbandonata era di 75 giorni. Ora, è di una manciata di ore. È diventato comune fare esperienza della cosiddetta decadenza dei link (vale a dire, di link che rinviano a risorse online non più operanti).
Una pagina web che si aggiorna costantemente è un sito che non conserva memoria del proprio passato, e lo stesso sistema dinamico che consente di riscrivere migliaia di volte lo stesso documento rende altamente improbabile la conservazione delle versioni precedenti per un esame futuro.
“Salva questo documento” significa “sostituisci le versioni precedenti”, per cui ogni documento digitale di qualsiasi genere è destinato a questa natura astorica. Il rischio è che le differenze siano cancellate, le alternative amalgamate, il passato costantemente riscritto e la storia ridotta a un perenne qui e ora.
Quando la maggior parte della nostra conoscenza è nelle mani di tale memoria che dimentica, possiamo trovarci imprigionati in un eterno presente.
Vi è anche il potenziale rischio catastrofico di immense quantità di dati create simultaneamente. Ricordiamoci che la maggior parte, se non la quasi totalità, dei nostri dati è stata creata nel giro di pochi anni.
Tutti questi dati stanno già invecchiando e raggiungeranno insieme la soglia di arresto del sistema, come una giovane generazione che decidesse di andare in pensione allo stesso momento.
Dove sta dunque il problema? Contrariamente alla nostra passata esperienza, le aspettative di vita dei supporti dei nostri dati sono al momento pericolosamente sincronizzate. Si potrebbe raffigurare tutto ciò come una sorta di “boom demografico”: i big data invecchieranno e diventeranno dati morti insieme.
Naturalmente, grandi quantità di dati saranno registrati e trasferiti su altri supporti a intervalli regolari. Consideriamo il passaggio dei film in bianco e nero su nuovi generi di supporti o della musica dal vinile al cd. Ingenti quantità di dati sono stati trascurati andando persi o diventando indisponibili o inaccessibili.
Secondo una stima dell’Ibis World, l’industria del recupero dati ha conosciuto una diminuzione del proprio fatturato nell’anno corrente del 6,6 per cento sul totale di un 8,5 miliardi di dollari, con un continuo declino dal 2011.
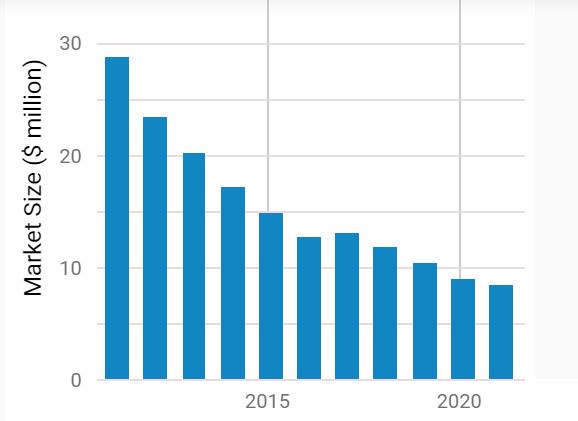
Questo risultato può apparire controintuitivo, dal momento che i big data sono in crescita e con loro i problemi relativi a sistemi di immagazzinamento dei dati e a file danneggiati, alterati o inaccessibili.
Ma l’industria che si prende cura di tali problemi non dovrebbe essere in pieno sviluppo? Ciò può spiegarsi con il fatto che il cloud e l’immagazzinamento online hanno ampliato le possibilità di recuperare dati o di prevenirne la perdita.
Si pensi agli strumenti Google drive, Onedrive, Apple iCloud o applicazioni simili. Se il proprio computer è danneggiato, e i file sono ancora disponibili online, si possono facilmente recuperare, cosicché non c’è bisogno di far ricorso a un servizio di recupero dati.
Il cloud computing ha messo in crisi l’industria specializzata in computer e hard disk. Quanto più i nostri dispositivi divengono meri terminali, tanto meno dobbiamo preoccuparci dei dati. Tuttavia, l’’immagazzinamento di tali dati continua a fare affidamento su infrastrutture fisiche, le quali richiedono una crescente manutenzione.
L’industria del recupero dati tende a scomparire, mentre una nuova industria dedicata ai fallimenti del cloud computing sta emergendo. Non si tratta però di fare affidamento sulla forza bruta della ridondanza (detenendo più di una copia dello stesso file).
Non è intelligente praticare questa strategia a livello globale, a causa dell’norme quantità di memoria digitale richiesta.
Pensiamo al nostro smartphone, troppo pieno perché troppo carico di foto, e proiettiamo questo problema su scala globale. Nella storia, il problema riguardava ciò che era da salvare: quali leggi o nomi sarebbero stati cotti in argilla o scolpiti nella pietra, quali testi scritti a mano su papiri o velli, quali nuovi soggetti stampati su carta.
Nell’era dell’informazione, salvare è l’opzione di default. Il problema diventa cosa cancellare. Dal momento che la capacità di immagazzinamento è insufficiente, qualcosa deve essere cancellato, riscritto o neppure registrato. Di default il nuovo tende a spingere via il vecchio (first in last out) ovvero “il primo che entra è l’ultimo ad uscire”: pagine web aggiornate cancellano quelle vecchie, le nuove foto rendono obsolete le precedenti, i nuovi messaggi sono registrati sopra i vecchi, le email recenti sono conservate a spese di quelle dell’anno prima.
Non c’è un nome codificato per questa “legge” relativa alla progressiva riduzione di memoria, ma sembra che il gap raddoppi ogni anno. Impedire significative innovazioni tecnologiche nell’ambito dell’immagazzinamento fisico o della compressione software renderà il processo peggiore dal punto di vista quantitativo (dati potenzialmente inutilizzabili in crescita). La buona notizia è che le cose non stanno così male come sembra dal punto di vista qualitativo.
Parafrasando un modo di dire comune nell’industria pubblicitaria, “metà dei nostri dati sono spazzatura” (dunque benvenga cancellarli!), il fatto è che non sappiamo quale metà. Siamo contenti di scattare dieci foto, perché speriamo che una venga bene e potremo scartare le altre nove, che non avevamo l’intenzione di conservare fin dal principio.
Ciò significa che abbiamo bisogno di capire meglio quali siano i dati che vale la pena preservare e curare, e questo dipende, a sua volta, dalla nostra capacità di comprendere quali siano le domande interessanti da porre, non soltanto oggi ma anche nel futuro.
Dovremmo presto essere in grado di chiedere agli algoritmi quali dati meritino di essere conservati. Si pensi ad un’applicazione nel nostro smartphone che non si limiti a suggerire quale delle dieci foto valga la pena tenere ma che impari anche dalle decisioni che prendiamo al riguardo (per esempio, che preferiamo le foto più scure).
In questa prospettiva, le nuove sfide avranno a che vedere con la nostra capacità di evitare decisioni basate su sistemi automatizzati rudimentali, di migliorare il cosiddetto apprendimento automatico e di assicurarci che le macchine riapprendano le nostre nuove preferenze (in un momento successivo della nostra vita potremmo preferire le foto più chiare).
Sistemi “intelligenti” possono aiutarci a decidere quali informazioni salvare e custodire, senza perdere di “memoria”, senza disperdere il passato attraverso un semplice click “sovrascrivi questo documento”
Il nostro storico del futuro avrà ragione nell’interpretare l’età dei petabyte nell’era dell’informazione come un momento di transizione tra i big data ciechi e quelli dotati di vista.
LINK UTILI:
The Average Lifespan of a Webpage
Data Recovery Service

Sono un ricercatore presso Co.Mac – CFT, un importante gruppo italiano che opera nell’ambito degli impianti industriali. Laureato in ingegneria Meccanica con specializzazione in Meccatronica al Polimi. Attualmente studio automazione con particolare focus verso gli algoritmi di intelligenza artificiale e le sue applicazioni nel mondo reale.
Comunicare significa donare parte di noi stessi, ed è questo il motivo per cui la divulgazione scientifica è una delle mie più grandi passioni.






