Le reti neurali tra creatività e arte
5 min read
Col diffondersi dei social network, cioè di ampie piattaforme di condivisione di contenuti e immagini, le fotocamere sono entrate prepotentemente nei dispositivi mobili. Ormai tutti i cellulari hanno in dotazione fotocamere sempre più sofisticate e con caratteristiche che difficilmente possono essere considerate amatoriali.
Il software che gestisce la macchina fotografica permette di scattare fotografie in modalità diverse, automatiche e manuali. Spesso è possibile effettuare complesse elaborazioni delle immagini acquisite. Da qualche anno a questa parte è comparso nello schermo un elemento che ormai consideriamo normale se non addirittura necessario: il rettangolino che individua e racchiude automaticamente i volti delle persone presenti nell’inquadratura. La novità è chiaramente legata alla possibilità di associare la figura presente nella foto al nome di una persona conosciuta. In questo, il software sfrutta una particolare tecnica di intelligenza artificiale chiamata reti neurali convoluzionali (apprendimento profondo).
Queste particolari reti neurali sono in grado di analizzare le immagini e inferire la presenza o meno di un particolare oggetto, di un viso o di una parte del corpo umano. Uno dei test principali di queste tecnologie è stato per anni ImageNet. È un enorme database composto da più di 14 milioni di immagini divise in diverse categorie (dai treni ai fiori). Il dataset di immagini viene tuttora usato per allenare le grandi reti neurali a riconoscere i contenuti. Nell’analizzare le immagini un individuo commette mediamente il 5 % di errori; ogni 100 immagini, quindi, un uomo di norma sbaglia ad identificare il contenuto di un’immagine per cinque volte. Questi risultati erano imbattibili fino a qualche anno fa e questa attività umana era tra quelle molto difficili da battere, fino a quando la capacità computazionale, ha permesso di allenare reti neurali particolarmente complesse.
È il caso della rete neurale progettata da un team di ricercatori di Microsoft, che nel 2015 è stata in grado di riconoscere oggetti con performance superiori a quelle di un essere umano. È interessante notare come, ancora una volta, la tecnologia abbia trovato ispirazione nei sistemi biologici: le reti convoluzionali trovano infatti le loro basi nella corteccia visiva del cervello. Queste reti sono progettate per simulare la struttura di questa area del cervello, che riceve le informazioni dal nervo ottico e le processa attraverso diversi livelli di neuroni; i livelli più bassi individuano lati o spigoli (dell’oggetto) e i livello successivi compongono parti che diventano via via più complesse.
Le nostre foto, o più in generale le immagini scattate dai nostri dispositivi non sono semplicemente quadratini colorati racchiusi in un’area bidimensionale: sono veri e propri contenitori di informazioni e concetti. Google Foto, per esempio permette di ricercare tra le proprie immagini archiviate non solo per posizione geografica o per data ma anche per contenuti: provate a cercare un “ombrello” tra le vostre foto archiviate.
Ormai sono molto diffuse le app che permettono di trasformare una determinata immagine applicando filtri preconfezionati. Tra i tanti filtri ce ne sono alcuni che trasformano l’immagine in qualcosa di simile a un’opera d’arte. È capitato a tutti noi di vedere, nel web o in qualche pubblicità, una foto trasformata in un quadro di Van Gogh o in un opera di De Chirico, che sembra dipinta davvero dall’artista. Queste applicazioni usano tecniche moderne di intelligenza artificiale in grado di emulare lo stile del pittore.

Negli ultimi anni, si sono fatte strada nuove forme di reti neurali la cui struttura è in grado di apprendere gli stili di pittori, di musicisti e di molte altre forme d’arte. Questa tecnologia si chiama Generative Adversarial Network (GAN) e si basa su un meccanismo molto semplice da descrivere quanto complesso da mettere in atto.
Si tratta di sistemi in genere composti da due reti neurali che lavorano in simbiosi. Invece che utilizzare esclusivamente dati reali, il sistema si basa su un procedimento generativo. Una rete, chiamata il discriminante, è deputata a riconoscere se un particolare input rappresenta un originale o un falso e viene “ricompensata” quando indovina. La seconda rete neurale invece, ha come obiettivo quello di generare dei falsi che devono essere sottoposti al discriminante con lo scopo di trarlo in inganno.
Questa seconda rete viene ricompensata quando riesce nell’intento di imbrogliare la prima. La ricompensa è intesa come un incremento di una funzione matematica che rappresenta una sorta di punteggio che la rete neurale deve riuscire a massimizzare.
In sintesi, se vogliamo creare un’immagine artificiale di una ragazza bionda, partiamo dal rete generatrice alla quale chiediamo di generare un’immagine, appunto di una ragazza bionda. Una volta generata l’immagine, la diamo in pasto alla rete neurale discriminante la quale dovrà rispondere al quesito: questa immagine contiene una persona vera? Se la risposta è no, si torna indietro dalla rete generatrice e le si comunica: Attenzione, è un fake! E le si chiede di riaggiustare i parametri e “risistemare” l’immagine che attualmente è considerata inaccettabile.
A questo punto la rete generatrice ne modifica leggermente il contenuto per renderla “vera”; la nuova immagine (modificata) viene sottoposta successivamente al test della rete discriminante. Se l’esito è positivo, il processo di creazione dell’immagine si conclude, in caso contrario, il procedimento di riaggiustamento si itera nuovamente fino a quando il test non viene superato.
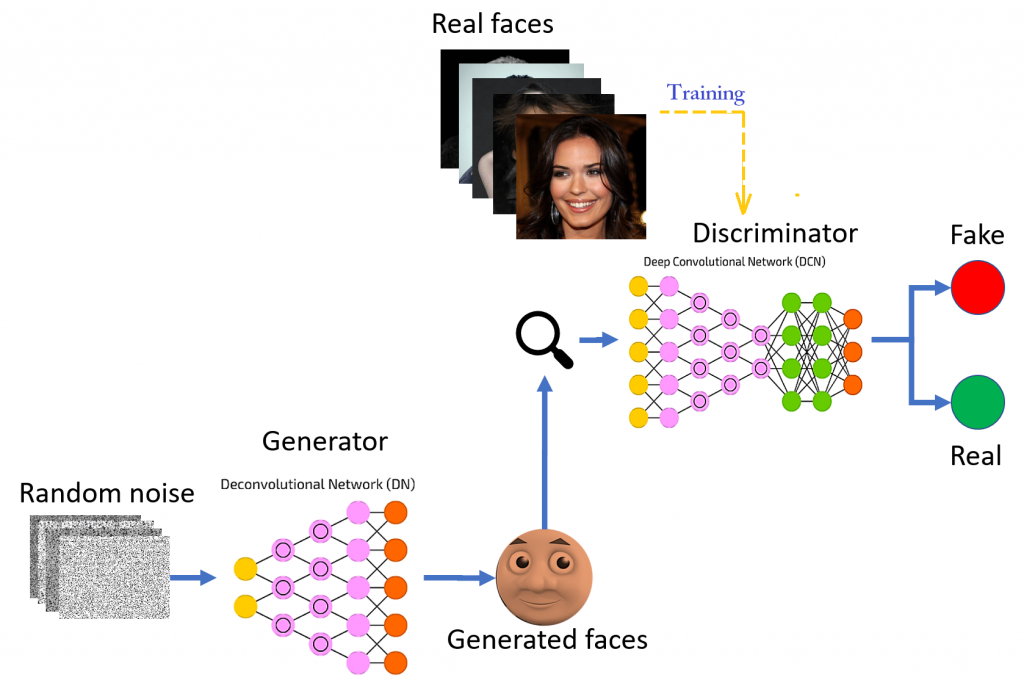
La simbiosi risulta quindi in una partita tra due avversari che devono avere la meglio l’uno sull’altro, in cui una deve creare il falso, e l’altra deve verificare la presenza del “vero”. All’inizio della fase di addestramento, la rete falsaria produce delle informazioni che sono chiaramente intercettabili e riconoscibili come fasulle poiché sono tipicamente di bassa qualità. Ma mano a mano che l’addestramento avanza diventa sempre più abile nella generazione delle informazioni, tanto da riuscire ad ingannare la controparte. Nella fase finale, la qualità delle informazioni fasulle generate è quasi del tutto identica a quelle reali.
Supponiamo quindi che la rete discriminante debba riconoscere se l’artista che ha prodotto un particolare quadro, rappresentato da un’immagini in input, sia effettivamente Van Gogh, la rete falsaria imparerà a generare immagini il cui stile sia il più vicino possibile a quello dell’artista. Questi strumenti sono considerati particolarmente avanzati e inducono criticità importanti nella nostra quotidianità. Sono in grado di generare immagini, video, notizie, audio che pur non rappresentando la realtà sono difficilmente distinguibili dal vero.
Particolarmente virali sono diventati i video fasulli di personaggi famosi che realizzano artefatti o raccontano storie che non sono mai accadute. A fine agosto 2019, il Washington Journal riportava il primo caso di deepfake attack, nel quale veniva chiesto ad un impiegato di un’azienda di fare un bonifico di 243 mila dollari a un fornitore. La richiesta veniva fatta telefonicamente dall’amministratore delegato, seguendo una normale procedura aziendale. In questo caso, però, la voce era stata riprodotta in modo da simulare il tono di voce del titolare attraverso l’uso delle reti neurali.
LINK UTILI:
Raudsters used AI to mimic CEO’s voice in unusual cybercrime case
Art with AI: turning photographs into artwork with neural style transfer
Il pensiero artificiale

Sono un ricercatore presso Co.Mac – CFT, un importante gruppo italiano che opera nell’ambito degli impianti industriali. Laureato in ingegneria Meccanica con specializzazione in Meccatronica al Polimi. Attualmente studio automazione con particolare focus verso gli algoritmi di intelligenza artificiale e le sue applicazioni nel mondo reale.
Comunicare significa donare parte di noi stessi, ed è questo il motivo per cui la divulgazione scientifica è una delle mie più grandi passioni.






